Operační systémy 2
Vojtěch Netrh
poslední aktualizace: 5. června 2024
Operační pamět
- zásadní význam pro kód (z pohledu OS stejně důležité jako CPU)
- taky přístup k zařízením (např. DMA)
- realizovaná pomocí různých způsobů
- o přídělování/uvolňování by se měl starat OS
Požadavky na správu paměti
- program by neměl být závislý na místě v paměti
- izolace procesů (ochrana) je zásadní
- sdílení - kvůli komunikaci procesů či 2x spuštěný stejný program nebo sdílení knihovny
- organizace
- logická (sekvence bytů)
- fyzická (více různých nosičů - RAM, disk) - zase abstrakce
Adresní prostory
- každý proces má vlastní prostor (nezávislost)
- fyzická pamět se mapuje do adresního prostoru procesu
Rozdělení na souvislé bloky
- nejjednodušší rozdělit na bloky stejné velikosti
- potřebuje víc → sám se stará o načtení/přesun
- potřebuje méně → neefektivní využití (= vnitřní fragmentace)
- rozdělení na bloky různých velikostí (lepší řešení)
- fronty (každá pro procesy, co se vlezou do dané paměti)
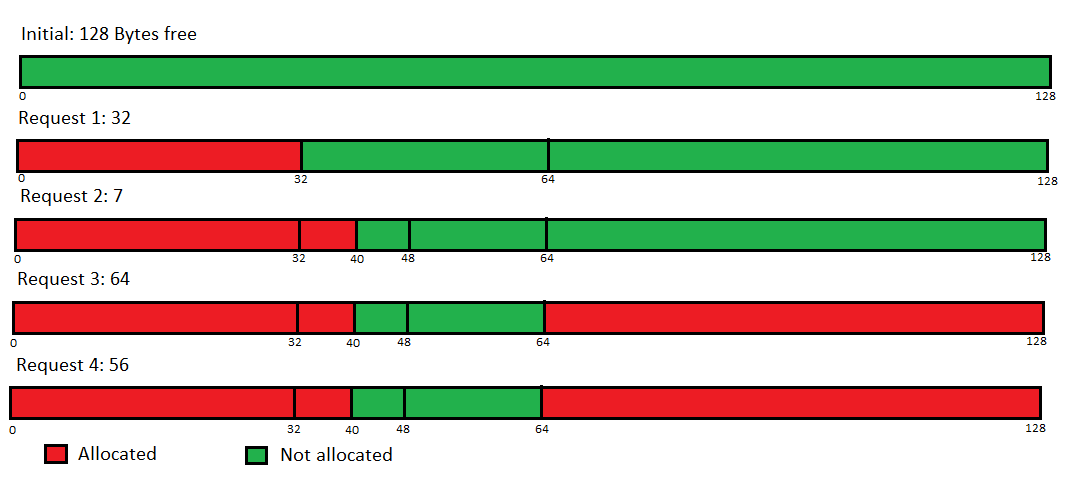
Přidělení bloků proměnlivé velikosti
- každý proces tolik kolik potřebuje (⇒ snížení vnitřní fragmentace)
- dochází k vnější fragmentaci
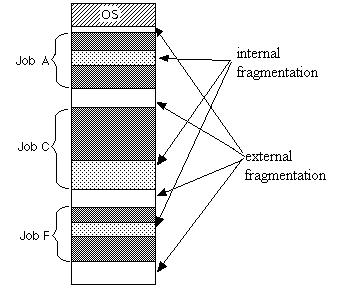
- můžeme mít různé strategie přidělování
- first fit - první volný blok
- next fit - prohledává od místa, kam umístil naposledy
- best fit - přiřadí nejmenší vyhovující blok
- worst fit - vezme největší blok
- informace uloženy v bitmapě či seznamu volného místa
Buddy alokace
- kompromisní řešení
- snižuje vnější fragmentaci, vnitřní má střední míru
- postup
- nejdříve celá pamět jako jeden velký blok
- žádost o kus paměti
- systém děli pamět na poloviny (mocniny 2) a přidělí nejmenší možnou
- při uvolnění se naopak snaží co nejvíce paměť spojovat
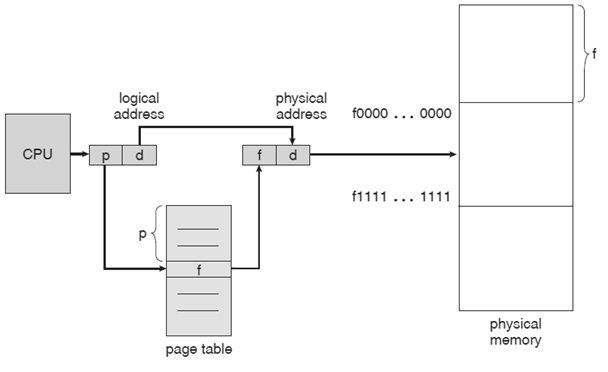
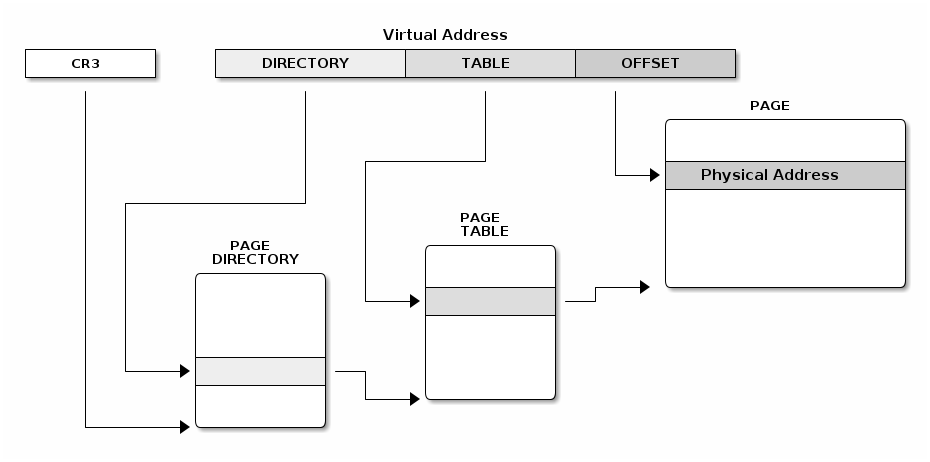
Stránkování
- logický prostor je rozdělen na menší části = stránky
- fyzická pmět je dělena na stejné úseky = rámce
- mapování stránek na rámce (nutný překlad adresy)
- výpočet fyzické adresy je implementován hardwarově (kvůli efektivitě)
- stránkovací tabulka (page table)
- logická adresa - … číslo stránky, … offset
- fyzická adresa - … číslo rámce v tabulce stránek příslušného
- celkem jednoduché fungování
- program není jako celek v paměti, ale je na měnší “kousky”
- systém vidí pouze stránky (nikoliv rámce)
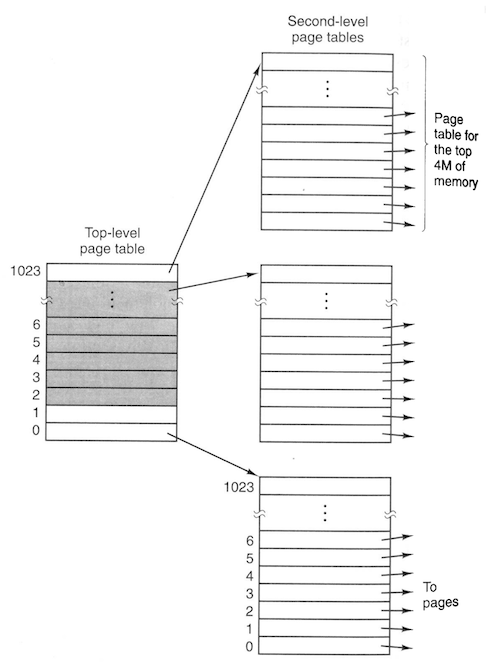
Adresář stránek
- velikost stránek je vždy mocnina 2 (klasika už)
- velikost stránky 4 kB a adresní prostor 32 bitů ⇒ adesní tabulka má 1 milion záznamů
- tabulku musíme někde udržovat → nepraktické ji mít tak velkou → víceúrovňové tabulky (až 5 úrovní)
- příznaky pro režijní informace
Translation lookaside buffer (TLB)
- cache pro hojně používané části stránkovacích tabulek
- zavedeno jelikož by operace jinak byly velmi pomalé
- 99 % typicky cache hit (1 hodinový cyklus CPU)
- zbylé případy se adresa načte (10-100 cyklů)
- průměrný přístup je 1.5 hodinový cyklus
- princip lokality - ideální aby daty, ke kterým přistupujeme byly na jednom místě
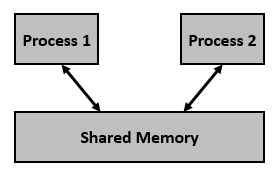
Sdílená paměť
- proč? komunikace a šetření místa
- v praxi jsou stránky více procesů jsou navázány na jeden rámec (poskytuje i izolaci procesů)
- CoW (copy on write)
- jde o příznak stránky, zakáže zápis do stránky
- data se při kopírování neduplikují ihned, ale až při pokusu o změnu
+úspora míst,-malinko větši režie- používá se pouze při sdílení
- např.
fork()
Segmentace
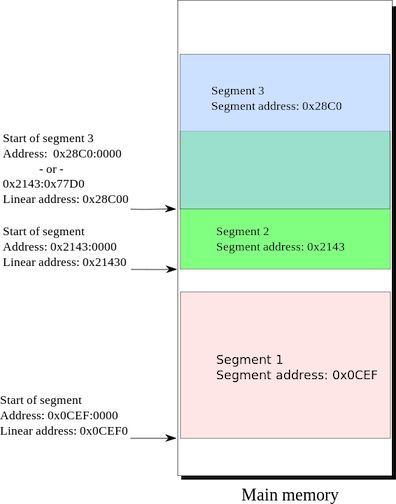
- starší než stránkování
- pamět dělena na několik segmentů (podle logického významu - kód, data, zásobník, ostatní)
- pomezí jádra a programu
- ochrana (stanovena horní a dolní hranice segmentu ⇒ mimo tuto oblast se nedostanu)
- CS (code segment) - implicitně z brány kódového segmentu
- SS (stack segment) - při přístupu přes ESP/EBP
- DS (data segment) - ostatní instrukce
- dále - ES, TS, GS
- logické adresa má 48 bitů (16 selektor a 32 offset)
- deskriptory segmentu - popisují segment (báze, limit, úroveň oprávnění)
- GDT - global description table (sdílená)
- LDT - local description table (každý proces má vlastní)
- registry GDTR, LDTR
- báze segmentu + offset = lineární adresa (10 + 10 + 12 bitů) ⇒ fyzická adresa
- hierarchická struktura
- page directory
- page tables
- úroveň oprávnění
- čtyři úrovně ring (0-3)
- ring 0 - jádro - nejvyšší oprávnění
- ring 3 - uživatelské procesy - nejmenší
- přechod přes gates či speciální instrukce
Typy adres na i386
- logická adresa
- pracuje s ní program
- 48 bitů (16 selektor segmentu, 32 offset)
- instrukce brány z CS (code segment)
- přístup do paměti přes ESP či EBP (registry) a používá SS
- zbytek využívá DS (data segment)
jmp 0xdeadbeef // --> jmp cs:0xdeadbeaf
mov eax, [esp + 4] // --> mov [ss:esp + 4]
mov eax, 0x12345678 // --> mov [ds:0x12345678]
mov eax, [gs:ebx + 10] // explicitni pouziti segmentu- lineární virtuální adresa
- 32 bitů
- finální adresní prostor procesu
- fyzická adresa
- přímo číslo bytu
- sdílena s dalšími HW zařízeními
Segmentace i386
-
každý segment má oprávnění
-
deskriptor pro segment (8B záznam) - báze, limit, ring x
-
deskriptory uloženy v GDT (global), LDT (local)
- max 8192 záznamů
- v GDT první “null deskriptor”
-
do segmentových registru je uložen selector (16 bitů) - ukazatel do GTD či LDT
-
při načtení se načte i deskriptor, ale nejde k němu přistupovat
-
segmentace = proces převodu logické adresy na lineární
-
ověřují se oprávnění a limit (aby se nešlo dostat za hranici)
-
báze segmentu + offset = lineární adresa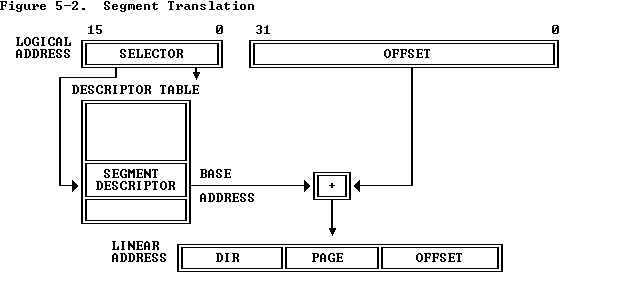
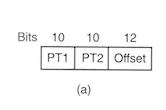
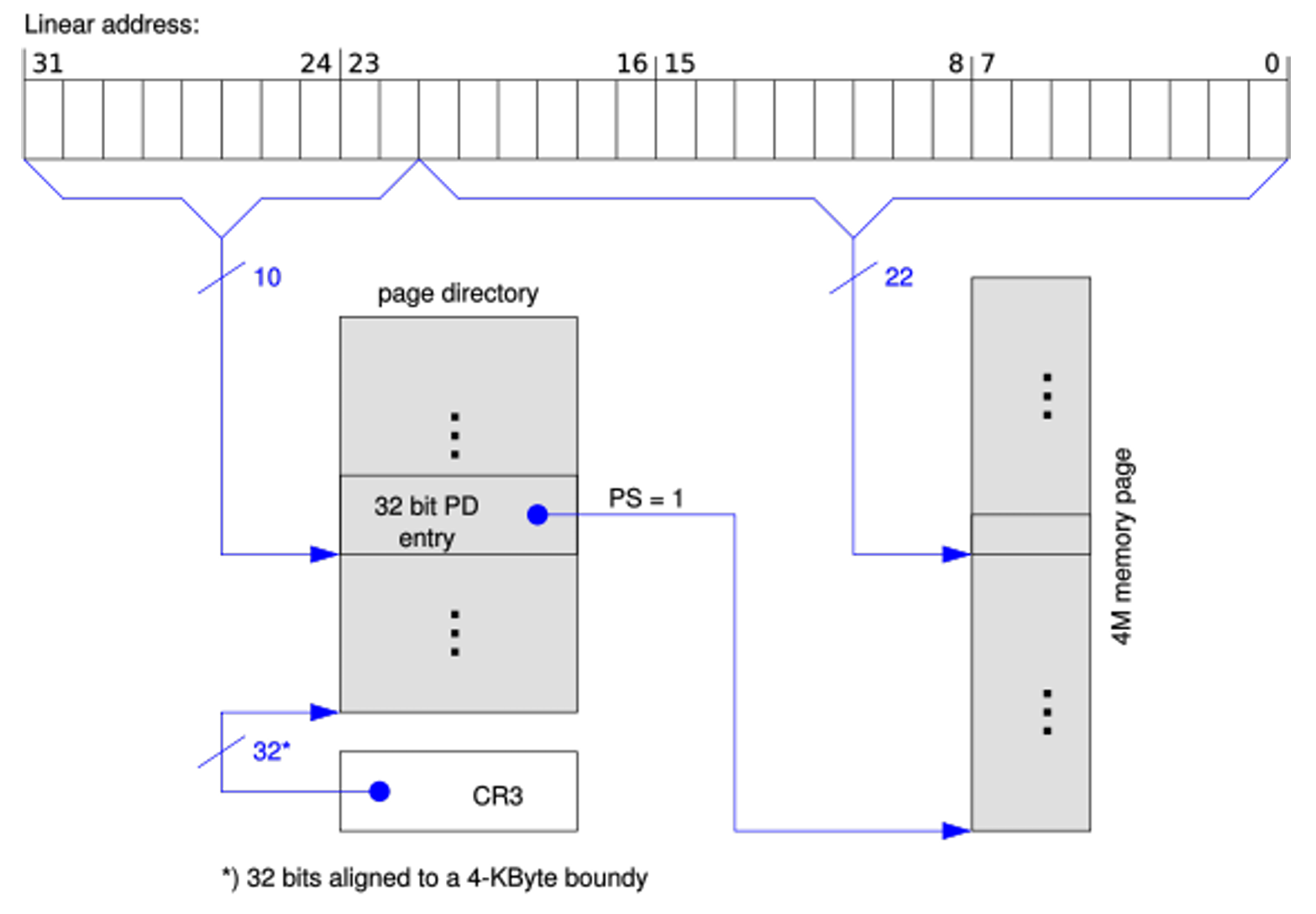
Stránkování i386
- převod lineární adesa ⇒ fyzická adresa
- stránka či rámec má 4 kB
- hierarchická struktura - page directory, page tables, offset
- adresář má velikost 1 stránky
- každá položka 4B ⇒ 1024 záznamů
- lineární adresa =
10 - 10 - 12 bitů (PDI - PTI - offset) - maximální kapacita 4 GB
- v PDT možno nastavit příznak a obejít přepočet → velikost stránky 4 MB → výsledek vypadá následovně
Physical address extension (PAE)
- umožňuj rozšířit RAM (4 GB na 64 GB)
- část adresního prostoru přesměruje do jiné části fyzické paměti
- stránky 4 KB/2 MB (normální / velké + offset 21 bitů)
- změna na úrovni OS
- tabulka opět 4 KB, ale záznam má 8 B ⇒ 512 záznamů (o 50 % méně)
- 3 úrovňové stránkování
- adresa dělena na
2 - 9 - 9 - 12 bitů 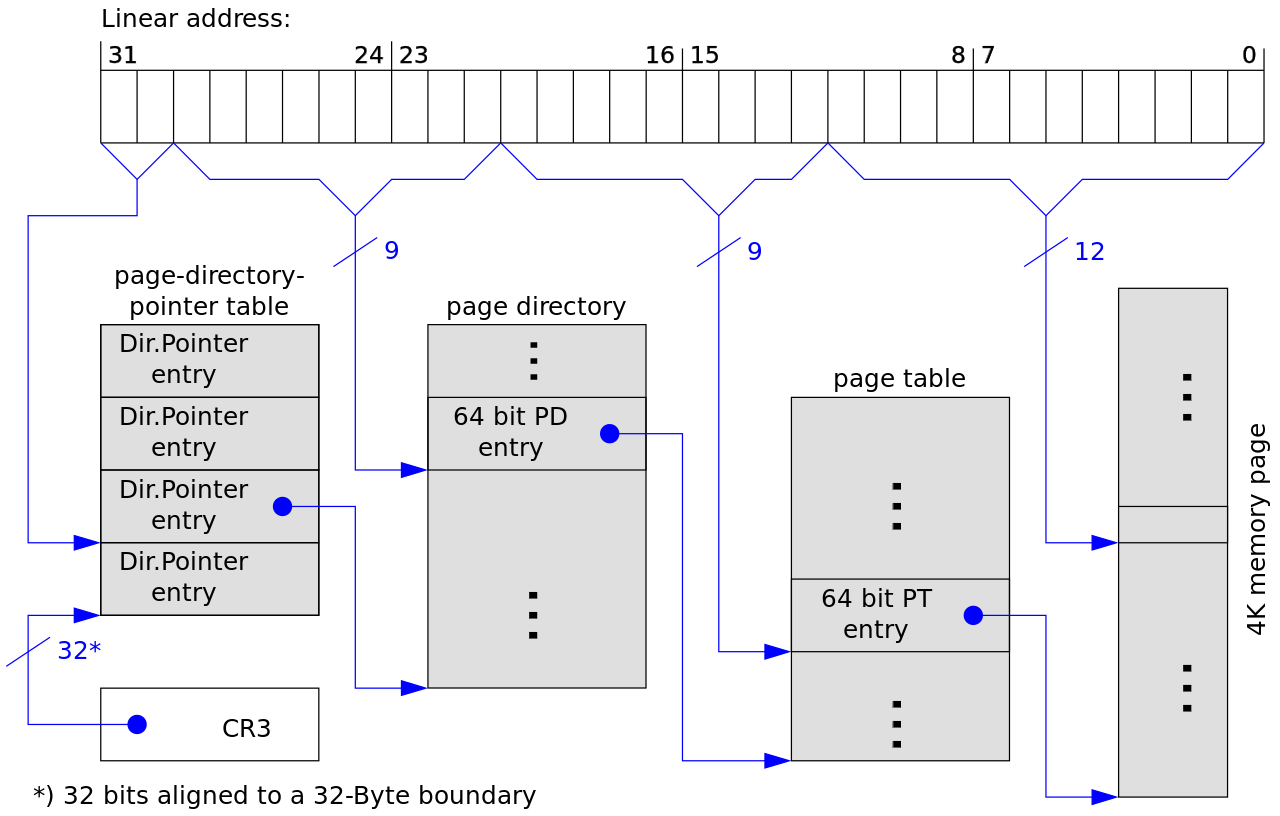
- PDPT - page directory pointer table
- adresář tabulek stránek
- jen čtyři 8B záznamy
Typy adres na AMD64
- segmenty pouze ke kontrole oprávnění
- deskriptor kódového segmentu k přechodu mezi 32 a 64 bitovým režimem
- současnost
- 36-46 bitů pro fyzickou adresu ⇒ 64 GB - 64 TB
- 48 bitů pro logické adresy ⇒ 256 TB
- budoucí rozšíření pomocí kanonických adres
Stránkování AMD64
- podobné jako PAE
- 4 úrovňová hierarchie
- záznamy mají 8 B
- 4 kB stránka -
9 + 9 + 9 + 9 + 12 = 48 adresovatelných bitů - u 2 MB stránek vynechána jedna úroveň (a použití 4 rezervovaných bitů ⇒ 52 celkem)
Ochrana paměti
- na úrovni segmentů nejde vypnout (pořád se bude provádět kontrola, ale přístup bude umožněn všude)
- probíhá paralelně ⇒ nedojde ke zpomalení
- co kontroluje?
- typ segmentu
- velikost segmentu
- oprávnění
- omezení instrukční sady
- omezení vstupních bodů
- omezení adresovatelné domény
- stránkování funguje souběžně se segmentací
- bit pro systémové stránky ⇒ zákaz přístupu z ring 3 (pouze přes spec. instrukce či gates)
- bit pro zákaz zápisu
void * simple_free(int size){ return sbrk(-size); }
- `brk()` ... argument je adresa "do které" má pamět rozšířit
- `sbrk()` ... argument je velikost o kterou má být paměť rozšířena
- uvolnění je jednoduché, ale způsobuje fragmentaci (do `size` se uvede záporná hodnota)
- **bloky zaokrouhleny** na dvojnásobek velikosti slova (32/64 bitů) -> minimálně 8 B
- každé vlákno může mít svůj alokátor
- nejmenší alokovatelný blok jsou 4 slova
- vždy začíná/vrací sudý násobek slova
- `malloc` nejdříve hledá volný blok, který byl již uvolněn, pokud nenajde -> oblast se rozšíří (2 strategie - FIFO v seznamech, best fit ve stromech)
- alokátor si udržuje informaci o tom, které bloky byly uvolněny
- menší bloky v 32 frontách
- větší bloky v 16 trie
- ostatní (největší) mají speciální strom
- zavolání free funguje na principu buddy systému pro následující a předchozí blok (slučování)
- malloc vybírá strategií
1) seznamy => FIFO
2) stromy => best-fit
### Windows
- API + frontend + backend
- každý objekt má hlavičku (8 B)
- **frontend**
- optimalizuje alokaci menších bloků
- 2 strategie
1) LAL (look aside list) - 127 s objekty velikosti `n * 8 B`
2) LF (low fragmentation) - až pro objekty do 16 kB
- **backend**
- podobný ptmalloc
- velké bloky přímo přes VM
- není k dispozici malý -> rozdělí se větši
### Automatická správa paměti (garbage collector)
- zjednodušený vývoj aplikací na úkor režie počítače (a aplikace jsou pomalejší)
- zásobník je rychlejší než halda
- **escape analysis** - analýza zda daný objekt může uniknout z daného kontextu (např. funkce)
- **region/aréna** = alokace velkého bloku paměti (předpoklad na společné uvolnění, menší režie než `malloc` a `free`)
- jak řešit automatickou správu?
1) **počítání odkazů - ARC - automatic reference counting**
- kolik na něj odkazuje objektů => pokud 0, tak smažu
- PHP, Python
- problém cyklické závislosti
![[memory_leak_reference 1.png]]
- řeší to překladač (Swift, ObjectiveC)
2) **objekty rozděleny do 3 množin**
1) **bílé** - kandidáti na uvolnění
2) **šedé** - odkazované z kořenu (musí se prověřit)
3) **černé** - mají odkazy na bílé objekty
- algoritmus
1) jeden šedý objekt se přebarví na černo
2) z něj odkazovné bílé objekty se barví na šedo
3) opakuje se dokud existují šedé
##### Varianty GC
1) **přesunující vs nepřesunující**
- přeskupení objektů, aby vytvořily souvislý blok
2) **generační**
- předpoklad: krátce žijící objekty budou žít krátce
- u starších objektů nemusí probíhat sběr příliš často
3) **přesné** vs **konzervatinví**
- v Javě, .NET
- odhadují zda je daná část objektu ukazatel
- finalizace: fronta objektů ke zrušení (`finalize()`, není zaručeno zda bude vůbec zavolána a kdy, spíše NEPOUŽÍVAT)
1) **inkrementální** vs **stop the world**
- inkrementální uvolňuje objekty po menších částech
- stop the world vše uvolní najednou (musí se zastavit)
- vylepšení paralelním zpracováním
2) **mark and sweep**
- každý objekt má příznak zda-li se používá
- při úklidu se objekty podle potřeby označí a ty neoznačené se uvolní
- nevýhody: špatná cache, vnější fragmentace
3) **kopírující GC**
- přesouvá objekty mezi aktivní a neaktivní částí (kopírovaných objektů je značně méně - jsou to ty aktivní)
- řeší problémy "mark and sweep"
- ![[copying_gc.gif]]
1. **manuální správa paměti**
- režie (CPU) - `malloc`
- uniklá paměť (`Valgrind`)
- možná finalizace
- neexistuje "stop the world"
2. **automatická správa paměti**
- rychlejší - malloc
- pomalejší uvolňování
- problém s finalizací
- nedeterminismus
<div style="page-break-after: always;"></div>
# Mezioprocesorová komunikace (IPC)
- procesy jsou oddělené, takže je nutné, aby spolu komunikovali
- proč? privilegia, zrychlení výpočtů, sdílení informací
- **několik kategorií**
1) **synchronizace**
2) **sdílená paměť**
3) **zasílání zpráv**
4) **vzdálené volání procedur**
- záleží i na tom jaké procesy spolu komunikují (cizí/příbuzné, zda jsou synchronizovány, jaká mají oprávnění atd.)
### Sdílená paměť
- procesy sdílí úsek paměti (nutná spolupráce správy paměti)
- velikost **zaokrouhlena** na násobek stránky (obvykle 4 kB)
- paměť může být **namapována na různé adresy**
- **Windows**
- mechanismus pro mapování souboůr do paměti
- `CreateFileMapping` a `MapViewOfFile`
- **Unix**
- `shmget` - najde úsek paměti s daným klíčem
- `shmat` / `shmdt` - napamuje/odmapuje sdílenou paměť
### Signály
- podobné přerušení
- v unixech **základní forma komunikace**
- nastane nějaká událost -> proces vyšle signál -> systém může reagovat
- proces může mít vlastní handlery pro tyto signály
- jsou celočíselné
- některé mají implicitní určení či implicitní handlery
- `SIGINT` - ukončení procesu (ekvivalent `ctrl + c`)
- `SIGSTOP` - pozstavení procesu
- `SIGKILL` - ukonmčení procesu (nezabklokovatelné)
- a další...
### Roury
- typické v unixu (podpora i ve Windows)
- umižňuje jednosměrnou komunikaci mezi procesy (jeden konec zapisuje, druhý čte)
- FIFO
- umožňuje kompozici do větší celků (v shellu - `cat fi.log | grep "11/11/2011" | wc-l`)
- využívá standardní výstup a vstup
![[Pasted image 20240131145033.png]]
- v linuxu je buffer 64 kB
- plný/prázdný jeden z procesů čtení/zápis pozsataven
- **pojmenované roury** ... soubor chovající se jako roura, komunikace nepříbuzných procesů
- **pseudo roury** ... systém emulující roury (vytváří mezisoubory)
### Zasílání zpráv
- obecný mechaninsmus (ale různé varianty)
- základní operace `send` a `receive`
- mohou být blokující i nebklokující
- 2 typy adresace
- **přímá** (pro kooperující procesy)
- **nepřímá** - zprávy se ukládají do fronty a odtamtud se čtou (varianty 1:1, 1:N, N:1, M:N)
- skládá se z **hlavičky** (typ, zdroj, cíl, délka, ...) a **těla**
- pomocí zasílání zpráv můžeme implementovat vzájemné vyloučení
- využití blokujícícho `receive`
- společná schránka obsahuje 1 či žádnou zprávu (=> funguje jako token, že (ne)lze vstoupit do kritické sekce)
##### Windows
- událostmi řízený systém
- zprávy zasílány oknům (vše je okno)
- "hlavní funkce" `WinMain`
- **remote procedure calls** ... klient volá zástupnou proceduru
<div style="page-break-after: always;"></div>
<div style="page-break-after: always;"></div>
# I/O zařízení
- zásadní složka ve Von Neumanově architektuře
- různé rychlosti, druhy přístupu i pohledy
1) **bloková zařízení**
- data přenášena v blocích stejné velikosti
- možno nezávisle zapisovat/číst jednotlivé bloky
- př. HDD, SSD, páska
2) **znaková zařízení**
- proud znaků/bytů (=> nelze posouvat)
- př. klávesnice, myš
3) **ostatní**
- hodiny (přerušení), grafické rozhraní (mapovaná paměť)
- dá se k nim přistupovat různým způsobem
1) **port-mapped**
- registry mají samostatný adresní prostor (oddělený od paměti)
- přístup přes operace `read/write`
1) **memory mapped**
- registry namapovány do paměti
- data se čtou/zapisují přímo na sběrnici
- výhodou je, že k zařízením se přistupuje stejně jako k paměti
- oba tyto režimy vyžadují CPU
- bez účasti CPU lze **vyřešit pomocí DMA** (direct memory acces)
1) řadič DMA (neboli DMAC) dostane požadavek (čtení + adresa)
2) předá ho řadiči disku
3) zapisuje data do paměti
4) dokončení oznámí řadiči DMA
5) DMAC vyvolá přerušení
- PCI zařízení nepotřebuje DMA (PCI bus master)
### Přístup k I/O
- měl by zajistit OS
- stejné rozhraní bez ohledu na typ zařízení
- synchroní a asynchroní (blokováno dokud není dokončeno vs program pokračuje dál i bez dokončení)
- výlučný a sdílení přístup (pouze 1 proces v čase vs více procesů současně)
1) **aktivní čekání**
- kopíruje se z bufferu do registru zařízení (či opačně)
- stavový registr říká kdy jsou přenesena
- jednoduché, ale neefektivní
2) **I/O s přerušením**
- není nutné čekat na dokončení
- přenos řídí obsluha přerušení
3) **I/O přes DMA**
- analogicky jako 2., ale řídí DMA
4) **bufferování**
- optimalizace (poždění zápisu/čtení)
- **vrstvy I/O z pohledu OS**
![[Pasted image 20240212155314.png]]
1. **PMIO** - port mapped
- specifické intrukce pro komunikaci
- oddělený adresní prostor
- pomalejší
2. **MMIO** - memory mapped
- pomocí standardních instrukcí pro práci s pamětí
- rychlé
3. **DMA** - direct memory acces
- umožní zařízení přístup do paměti bez účasti CPU
- procesor se může věnovat své práci
- nutná synchronizace
##### Ovladače zařízení
- zajíšťují přístup k zařízení
- obvykle součást jádra OS
- **hardware abstraction layer**
- perspektiva ve Windows
![[Pasted image 20240213165835.png]]
### Bloková zařízení
### HDD
- disk - plotny, stopy - cylindry
- sektor 512 B - 4096 B
- **LBA** - logical block addressing
- **low-level formát** = hlavička + data + ECC
- rychlost přístupu ovlivněna
1) seek time (zásadní) = nastavení hlavičky na cylindr
2) rotace pod hlavičku
3) přenosová rychlost
- optimalizace možno provést ve více směrech
- cache disku, sektory -> clustery sektorů, cache OS, write-through cache, write-back cache
- **read ahead** a **free behind**
##### RAID - redudant array of independent disks
- verze 0-6
1) RAID 0 - zvýšení propustnosti
2) RAID 1 - mirroring (kopie), řeší selhání
4) RAID 3 - dělí data po bytech, XOR, disk pro paritu, zvládne výpadek 1 disku
5) RAID 4 - jako 3, ale používá bloky
6) RAID 5 - jako 4, ale paritní bloky jsou distribuovány
7) RAID 6 - jako 5, Reed-Solomon kód, výpadek až 2
8) *možnost spojovat - RAID10 je jako RAID 1 a RAID 0*
![[Pasted image 20240214133652.png]]
### SSD - solid state drive
- flash paměť
- SATA nebo M2
- **problematický přepis**
- omezený počet
- zápis po stránkách, mazání po blocích => zápis je rychlejší
- **wear leveling** - řeší problém, aby se určité části disku neopotřebovávali více než jiné (distirbuje opotřebení)
- garbage collection + TRIM (příkaz informující SSD o tom, které bloky mají nepoužívaná data)
### Optické disky
1) **CD**
- data ve spirále
- vysoká redundance
- efektivita jen 28 %
- 42 symbolů na rámec o 588 b (192 data, zbytek ECC)
- sektor má 2048 B dat, ale tvořen 98 rámci
1) **DVD**
- analogický jako CD, jen jiný laser
2) **blue-ray disk**
- opět jen jiný laser
### Znaková zařízení
- **terminál**
- většinou klávesnice + monitor => terminál
- samostantné terminály (RS-232)
- vstup a výstup řeší odlišné ovladače
- **2 možnosti** - předat buď přímo procesu (tzv. RAW mode) nebo počkat (backspace/cooked mode), ale ovladač musí mít buffer
- **speciální znaky** (`EOF`, `SIGQUIT`, `backspace`, ...)
- sofistikovaný příástup k výpisu textu řeší editory
- speciální znak `ESC` (př. `ESC\nA` => posun o $n$ řádku nahoru)
##### Hodiny
- krystal generující pravidelné pulzy (př. 1000 MHz)
- programovatelné -> nastavení registru na hodnotu (inicializace), každý pulz je snížení, při nule přerušení
- umožňují více funkcí - evidence času, uložení cache, plánování procesů
<div style="page-break-after: always;"></div>
# Souborové systémy a jejich implementace
- potřeba **uchovat větší množství dat** => primární paměť nesatčí
- perzistence dat
- vnější paměť a ukládání do souborů, které tvoří souborový systém
- **soubor** ... proud bajtů
- souborový systém **slouží jako abstrakce**
##### Operace se soubory
- `create`
- `write/append` - zápis či rozšíření, souvislé bloky či postupně
- `read`
- `seek`
- `erase`
- `truncate`
- `open` - otevření a manipulace přes **popisovač** (ukazatel na strukturu v jádře)
- `close`
- `get/set attribute` (práce s atributy)
- některé souborvé systémy nemuís určité operace podporovat
- pro práci se soubory možno využít existující nástroje
- roury, FIFO
- jeden soubor můžeme otevřít vícekrát (více ukazetelů)
##### Typy souborů
- běžné soubory, adresáře, unix: speicální soubory pro blokové a znakové zařízení
- 2 typy kódování - *binární* a *ASCII*
### Organizace souborů
- rozlišovány podle názvu (speicifikcé pro daný OS či FS)
- rozlišování malých a velkých písmen (`unix` vs `MS-DOS` vs `win`)
- `MS-DOS` - požadavek na jméno ve tvaru `8+3` (jméno + přípona)
- **rozlišení obsahu** má více možností
- podle přípony
- magická čísla (na unixu úvodní byty identifikují typ)
- podle metadat (informace o souboru uloženy vedle souboru)
- typická organizace do **adresářů** (obvykle **strom**)
- zápis pomocí lomítek (unix: `/usr/local/bin`, win: `\usr\local\bin`)
- **absolutní cesta** nebo **relativní**
- speciální adresář pro navigaci "nahoru" a "dolů" (`.` a `..`)
- v adresářích jsou taky operace - `Create, Delete, OpenDir, CloseDir, ReadDir, Rename`
- struktura nemusí být hierarchická, ale obecný graf
- **hardlink** ... ukazatel na tělo souboru
- **symlink** ... soubor obsahuje cestu k jinému souboru
### Organizace svazků
- každý (fyzický) disk složen z více (logických) částí (oddílů)
- ty jsou popsané pomocí **partition table** daného disku
- v každém oddílu souborý systém (= *svazek*)
- v `unixu` je svazek jako adresář, např. `/, /home, /usr`
- ve `windows` označeny písmeny (`a:, b:, c:`)
- je preferovaný jeden svazek pro vše
##### Virtuální souborobý systém (VFS)
- využití abstrakce -> kombinace více FS do jednoho
- specializované FS pro správu sytému (`procfs, sysfs`), které tvoří API OS
- možnost připojit jako běžný svazek
- síťové disky (NFS, CIFS)
### Struktura souborů
- **soubor** ... proud bajtů/více proudů/sekvence záznamů s pevnou strukturou/dvojice klíč-hodnota (čili více "definicí")
- více proudů se používá pokud si mít v rámci souboru více informací (např. video + zvuk + titulky + metadata)
- nutná podpora z OS
- k souboru připojeny i atributy (**metadata**)
- vlastník, práva, velikost, ...
### Přístup k souborům
1) **zamykání**
- sdílený přístup - musíme se postarat o synchronizaci
- omezení přístupu (současné čtení => zabránění zápisu)
2) **sémantika konzistence**
3) **práva přístupu**
- *ACL* ... acces control list
- seznam uživatelů s jejich právy (přířazení rolí)
- denied ACL
##### Oprávnění na Windows
- ![[Pasted image 20231128115951.png]]
- ve skutečnosti jde jen o logické oprávnění, které jsou abstrakcí nad jemnějšími oprávněními
##### Oprávnění na UNIX
- "ACL" pro vlastníka, skupina, zbytek
- novější implementace i plný ACL
- ![[Pasted image 20231128120216.png]]
- někde tyto oprávnění nemusí stačit
- další příznaky - `setuid, setgid, sticky bit`
<div style="page-break-after: always;"></div>
# Implementace souborových systémů
- souborové systémy pracujíccí s HDD či SSD
- očekáváme řadu věcí
- budou umět pracovat se soubory a disky adekvátní velikosti
- efektivní nakládání s místem
- rychlý přístup
- eliminace roztroušení dat
- odolnost proti poškození při pádu systém
- snapshoty
- komprese dat
- kontrolní součet
- defragmentace (za běhu)
- správa oprávnění
### Struktura disku
- lineární struktura
- rozdělení disku na oddíly (master boot record či GUID partition table)
- *sektor disku* ... základní jednotka (4 kB, starší 512 B)
- reálně větší bloky (1-32 kB)
- *jaká je optimální?* rychlost přístupu vs úspora místa
- závisí na tom s čím chceme pracovat
- není pevně daná
- nastavení při vytváření souborového systému
- **oddíl** má **vlastní souborový systém**
- nutné udržovat informaci o jednotlivých souborech, volném místu atd.
### Evidence volného místa
- *spojový seznam volných bloků* (v praxi trochu pokulhává)
- *bitmapy* - bit říká, zda je daná blok volný či nikoliv
- žadoucí zapisovat do souvislých volných bloků (heuristické algortimy)
- problém současného zapisování/kopírování 2 velkých souborů najednou
- ideální držet se do cca $95$ $\%$ zaplnění disku (fragmentace atd.)
- clusterování
### Adresáře
- organizace má vliv na výkon
- **různé struktury**
1) spojový seznam
2) hash tabulka
3) B-stromy
- umístění metadat
1) *součást adresáře* - soubor je svázán s místem v adresáři
2) *součást souboru* - v UNIX konkrétně v i-node)
##### Cache a selhání systému
- cache se používá **pro zrychlení** (odložení zápisu na disk)
- při výpadku se mohou data ztratit
- synchronní zápis (zpomalení, nemusí být zaručena konzistence)
- *soft updates* (uspořádání zápisů podle pravidel, složité pravidla dodržovat)
### Žurnálování
- dnes se hojně využívá
- data se zapisují **v transakcích** (nejdříve do žurnálu až pak na úložište)
1) po zapsání do žurnálu o tom jaké změny se provedou
2) po úspěšném zapsání je záznam označen značkou (kompletní zápis v žurnálu)
3) zápis dat na disk
4) po úspešném zápisu na disk je záznam vymazán
- připojení FS po chybě
1) chybí značka = transakce se neprovede (nebyla kompletní)
2) značka je = transakce se zopakuje
- pro zrychlení se do žurnálu zapisují jen metadata
- žurnál je cyklický
- nutné mít **atomické zápisy na disk**
- `cache` a `buffery` tuto techniku velmi ztěžují
- CoW (aktuální data se nikdy nepřepisují)
### FAT
- souborový systém pro MS-DOS
- jednoduchý (jména ve tvaru `8.3`, nepotřebuje oprávnění)
- disk rozdělen na **clustery**
- soubory popsány pomocí **file allocation table** (to je spojový seznam)
- disk rozdělen na **úseky**
- boot sector + informace o svazku
- 2x FAT tabulka
- kořenový adresář
- data
- adresáře jsou jako soubory
- původní FAT adresáře NEpodporoval
- ![[Pasted image 20240222085904.png]]
##### FAT varianty
- FAT12, FAT16, FAT32, ...
- zálěží na velikosti clusteru, ale i jiná omezení
1) **Virtual FAT**
- podpora dlouhých jmen (až 256 znaků) - jsou uloženy jako další záznamy va dresáři
- soubor má 2 jména (dlouhé a klasické 8.3)
2) **exFAT**
- pro flash paměti
- podporuje větší disky
### NTFS
- hlavní pro Windows NT
- velikost clusteru podle velikosti disku
- oproti FAT přidává práva a ochranu před poškozením
- žurnálování a transakce
- podporuje více streamů v jednom souboru
- dlouhé názvy, podpora POSIX
- *hardlink* ... přímo ukazuje na fyzickou adresu (sdílý i-node)
- *symlink* ... cesta k souboru/adresáři (má vlastní i-node)
##### Adresáře
- opět jako soubory
- jména v B-trees
##### Struktura disku
- na začátku *boot sector*
- 12 % **master file table (MFT)**, 88 % data
- **MFT** soubor popisující všechny soubory na disku (záznamy o 1 kB)
- 32 prvních souborů pro speciální určení (`$MFT, $MFTMirr, $LogFile, $Volume,` ...)
- v případě potřeby může 1 soubor zabrat více míst v MFT
- data v souboru popsána pomocí tabulky mapující *VCN* na *LCN*
- *virtual cluster number* ... číslo clusteru v souboru
- *logical cluster number* ... číslo clusteru ve svazku
- v tabulce jsou sloupce VCN - LCN - počet clusterů
##### B-stromy
- **vyvážené** stromy
- uzel alespoň $t - 1$ klíčů => $t$ potomků
- nejvýše pak $2t - 1$ klíčů => $2t$ potomků (plný uzel)
- rozdílné přístupové doby primární a sekundární paměti
- **sekvenční čtení** (načtení celých stránek)
- využívány v XFS, JS
### FS v linuxu
- nemá jeden hlavní (nejčastěji `ext4`)
- vychází z UFS
- až 256 znaků pro název
- *ext* je řada FS pro linux kernel
- `ext2` (vhodný pro flashky, rychlý a zbytečně nespotřebovává zápisy)
- `ext3` (přidal žurnál)
- `ext4` (další vylepšení)
- jsou navzájem zpětně kompatabilní (alespoň z velké části)
- další možnosti: BtrFS, JFS, XFS
### UNIX file system (UFS)
- v různých variantách v unixových OS
- disk je složen z
- bootblock (zavaděč OS)
- superblock (info o souborovém systému)
- místo pro i-node
- místo pro data
### i-node
- má pevnou velikost
- nese **info o souboru** (struktura ho popisující)
- typ, vlastník, oprávnění, počet ukazatelů, popisovače, časy vytvoření a přístupu
- 3 soubory odkazují na 1 i-node (= soubor má 3 jména) - to je případ *hardlink*
- informace o uložení dat (15 ukazatelů na bloky na disku)
![[Pasted image 20240222141406.png]]
- adresář jako sekvence dvojic (jméno a číslo i-node)
- struktura i-node **umožňuje řídké soubory**
- sporná velikost bloku (rychlejší přístup k větším souborům vs nevyužité místo)
- bitmapy pro evidenci volného místa
- svazek možno dělit na více skupin (každá funguje nezávisle)
### XFS
- navržen pro OS IRIX (pak i v linuxu)
- vhodný pro velké disky (nebo disková pole), interní 64 bitová adresace
- spoléhá na B-stromy (zaplnění alespoň ze $2/3$)
- disk dělen na agregační jednotky
- evidence taky v B-stromech (2 stromy)
- větší soubory používají B-stromy (zřetězení listů)
- malé adresáře v i-node
- žurnálování
### ZFS - zettabyte
- moderní
- kombinuje prvky LVM a RAID
- interně 128 bitová adresace
- disky spojeny do *poolu*
- FS se umí "rozprostřít" přes všechny
- *ditto block* ... replikace na více místech (pro poruchu sektorů primárně)
- **RAID-Z** - podobný RAID5, ale různě velké bloky (př. 3 data + 1 paritní)
- u dat evidovány kontrolní součty
- konzistence zajištěna CoW
### BtrFS
- vše uloženo v B-stromech
- existuje varianta podporující integritu
- jednoduchá implementace
- klíč jako
```c
struct btrfs_disk_key{
__le64 objectid;
u8 type;
__le64offset;
}
- slučování souvisejících dat
- automatická defragmentace
ISO-9660
- pro CD-ROM (podpora všech OS)
- zápis jen jednou, sekvenční čtení
- na začátku 16 + 1 rezervovaných bloků
- adresář popsán pomocí záznamů proměnlivé délky
- možnost formátu určena úrovněnmi (
level 1 až level 3) - rock ridge - kompatabilita s unix
- joliet - kompatabilita s windows
UDF - universal disk format
- náhrada za ISO-9660
- převážně u DVD a blue-ray
- různé varianty formátu - plain build, virtual allocation table, spare build
LVM - logical volume management
- problém: disky a oddíly mají pevnou velikost ⇒ přidání vrstvy mezi FS a blokové zařízení
- fyzický disk rozdělen na rozsahy
- může emulovat RAID, transparentně šifrovat
- na útoky jsou samozřejmě vázány tresty a trestní zákoník