Operační systém (úvod)
- abstrakce nad HW
- programátor chce být odstíněn od technických detailů/parametrů
- spravuje zdroje počítače (sdílení zdrojů)
Vrstvy
- HW
- OS
- standardní knihovny (libc, CRT)
- abstrakce nad OS (programy můžeme mezi nimi přenášet)
- systémové nástroje
- aplikace
-
situace s vrstvami je v realitě komplikovaná (virtualizace)
-
několik generací počítačů i OS (ty ze začátku nebyl vůbec)
- dnes se vytváří nová “generace” (bezpečnost - kontejnerizace, spotřeba)
Typy
- dělení podle více kategorií
- podle určení - mainframy, serverové, real-time, desktopové, mobilní, …
Architektura
- očekáváme: správa procesoru, správa paměti, komunikace procesů, obsluha zařízení, organizace dat
- není žádané, aby si toto programy implementovali sami
- jádro OS (kernel)
- 2 módy - kernel a user mode
Problémy s vývojem OS
- 2x tak důležité si stanovit cíl a konrétní potřeby
- je to hodně obecná definice a neznáme přesné použití
- definování primit, datových abstrakcí a izolace
- způsoby provádění programů (algoritmicky či událostmi řízené)
- způsob přístupu k datům (vše je páska/soubor/objekt/dokument)
- přenositelnost
- použitelnost SW vs vývoj HW
- nevyvíjet zbytečně velký (držet se skromnosti)
Architektura počítače
John von Neumannova
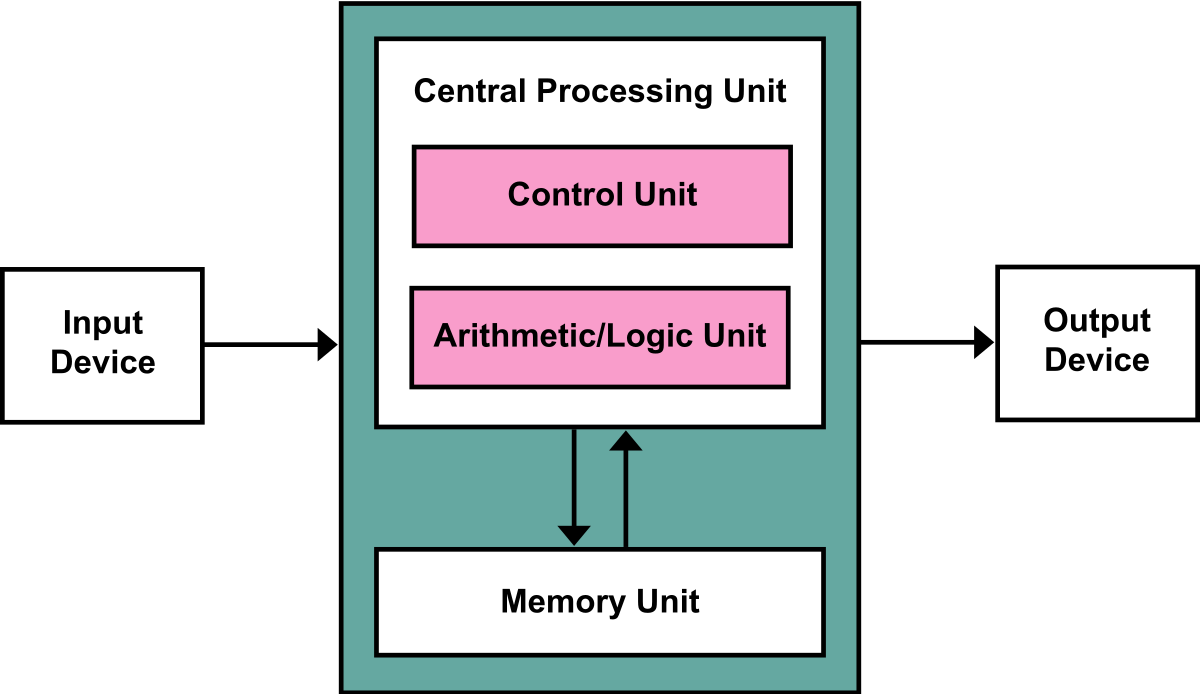
- instrukce zpracovány v řadě za sebou
- pamět společná pro program i data (rozdíl oproti harvardské)
CPU
- AL část (pro výpočty)
- řídící část (řadič) - spolupráce jednotlivých částí CPU
- registry (uchování právě zpracovaných dat, nejrychlejší přístup)
- ovládají i chod procesoru
- 4 důležité registry - IP, PSW (FLAGS), IR, SP
ISA (instručkní sada)
- sada instrukcí pro ovládání procesoru uložená v paměti (specifická pro danou rodinu CPU)
- reprezentováno jako strojový kód (čísla)
- 0-3 operandy (registr, konstanta, adres místa v paměti)
- porozumět instrukcím složité ⇒ vytvořen assembler (jazyk symbolických adres)
- umět uvést nebo porozumět něčemu zapsanému v ASM
- každá sada má charakteristické “vlastnosti”
- kroky pro zpracování instrukcí (opakují se v cyklu)
- načtení do CPU (Fetch)
- dekódování
- výpočet adres operandů
- přesun operandů do CPU
- provedení samotné operace
- uložení výsledku
- některé mohou být vynechány pokud je daná instrukce nepotřebuje
- pipelinning (zvýšení efektivity)
- paralelní zpracování instrukcí
- zvyšuje počet provedených instrukcí za jednotku času
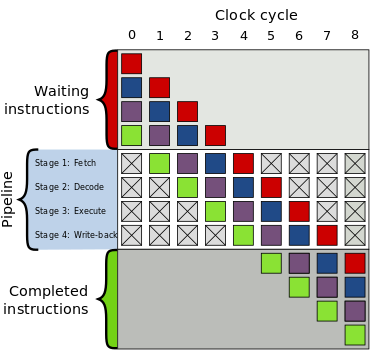
- superskalární procesory - více jednotek (typický jev)
- nutnost zajistit správně pořadí a synchronizaci
- Simultaneous multithreading (více vláken v 1 cyklu)
Architektura Intel x86/AMD64
- od 16 bit až po 64 bit (udržuje zpětnou kompatibilitu)
- různé typy registrů (pro různé účely)
- jsou 32 bitové (dají se dále dělit na menší = zpětná kompatibilita)
- rozšíření na 64 bitů (předpona R) -
RAX, RBX, ...- existuje pro každý registr
- přidání dalších registrů navíc
R8-R15
- možnost kombinovat 32 a 64 bitové instrukce libovolně
Základní souhrn instrukcí
 - r - registr
- m - adresa místa v paměti
- i - konstanty (max 32 bitů)
- Výjimky
-
- r - registr
- m - adresa místa v paměti
- i - konstanty (max 32 bitů)
- Výjimky
- MOV, ADD - nemohu přiřazovat mezi registry s rozdílnými velikostni
- MOVABS - r, i (až 64 bitů)

- místo
imůže být registr CL
- místo
Registr příznaků
- operace nastavují hodnoty bitů v registrech EF a RF
- každá má svůj specifický význam
- podíváním se na jejich hodnotu mohu zjistit informace o programu (co se stalo)
- SF - sign flag - výsledek byl záporný
- ZF - zero flag - výsledek byl nula
- CF - carry flag - došlo k přenosu mezi řády
- OF - overflow flag - přetečení mimo daný rozsah hodnot
- TF - trap flag - pro krokování
- IOPL - I/O privilege level - úroveň oprávnění (2 bity, pouze pro jádro)
- IF - interrupt enable flag - možnost zablokovat přerušení (pouze pro jádro)
Adresace paměti
- lineární strukruta (pevná délka, random přístup)
- přímá adresace (lineární)
- nevýhodné, při přesunu je nutné vše přepočítat
- nepřím adresace
- vzorec:
- konstanta - registr - registr - 1/2/4/8
- jakoukoliv část vzorce jde vypustit
- adresace je brána vůči začátku programu v paměti
BYTE8 bitů -WORD16 bitů -DWORD32 bitů -QWORD64 bitů- v prezentacích bez
PTR - slovo -
?WORDmohu vypustit, pokud je z registrů jasné o jakou půjde velikost
Zarovnání paměti
- procesor čte celé slovo (např. 32 bitů) ⇒ vhodné, aby pamět ležela na zarovnaném místě (rychlost + snažší implementace)
- některé CPU neumožňují číst NEzarovnanou pamět (či penalizují výpočet)
char 1B,int 4B, atd. (vždy jsou teda na adresách, které jsou násobkem jejich hodnot)- struktury zaokrouhlovány nahoru + dobré dát si pozor na pořadí datových typů ve struktuře
struct foo {
char a;
// mezera 3B
int b;
char c;
// mezera 1B
short d;
};Systémy reprezentace hodnot
-
pro různé procesory různé
-
pro systém uložení vícebitových hodnot se používá endianita
- little-endian : od nejméně významného (x86, amd64)
- big-endian : od nejvíce významného (SPARC, IBM power)
- bi-endian : lze přepínat (ARM, Power PC, SparcV9)
-
doplňkový kód (viz STRUP)
- záporná hodnota = provedeme inverzi bitů + přičteme 1
-
znaménkové vs neznaménkové
-
over/under flow (pokud se hodnota nevejde do rozsahu) ⇒ neočekávané výsledky
-
ASCII
- způsob kódování znaků
- 8 bitů
-
Unicode
- znaková sada (vazba číslo … znak)
- roviny po 65 535 znacích (110 000+ dnes)
- BMP - první roviny - znaky západních zemí
-
USC
- kódování znaků v Unicode
- pevně daná velikost
- USC-2 - 16 bitů / znak - základní rovina
- USC-4 - 32 bitů / znak - všechny znaky
-
UTF-8
- kódování znaků s proměnlivou délkou
- kompatabilní s ASCII
-
UTF-16
- kódování znaků s proměnlivou délkou
- rozšíření pro USC-2
- varianty pro BE a LE
- BOM - bite order mask
Řízení výpočtů a volání funkcí (podprogramů)
Příznaky
- hodnoty bitů v registru EF
- pro řízení výpočtu
- řídící příznaky
Skoky
- sekvenční zpracování instrukcí a místo
ifaloop, které neexistují, jsou skoky - co to je?
- přesun na jiné místo v programu (v ASM určeno návěštím)
- nepodmíněný
jmp(ekvivalentgoto) - podmíněný (až při splnění podmínky)
- signed
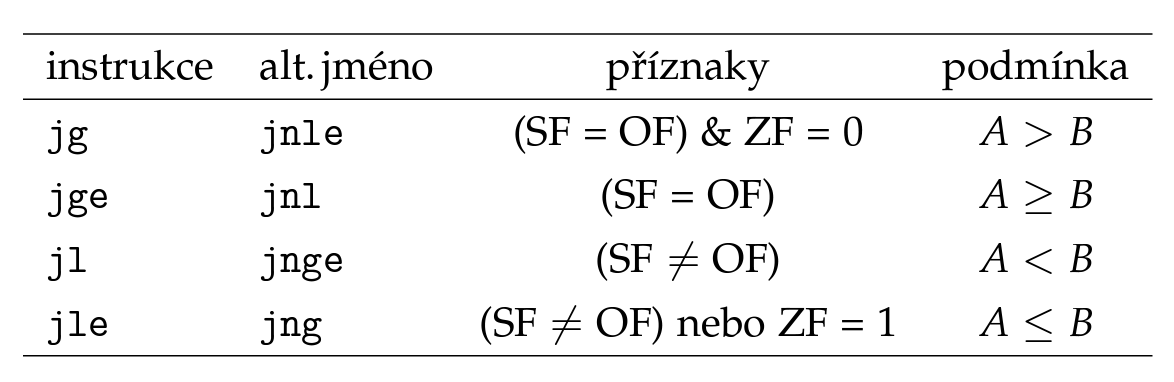
- unsigned
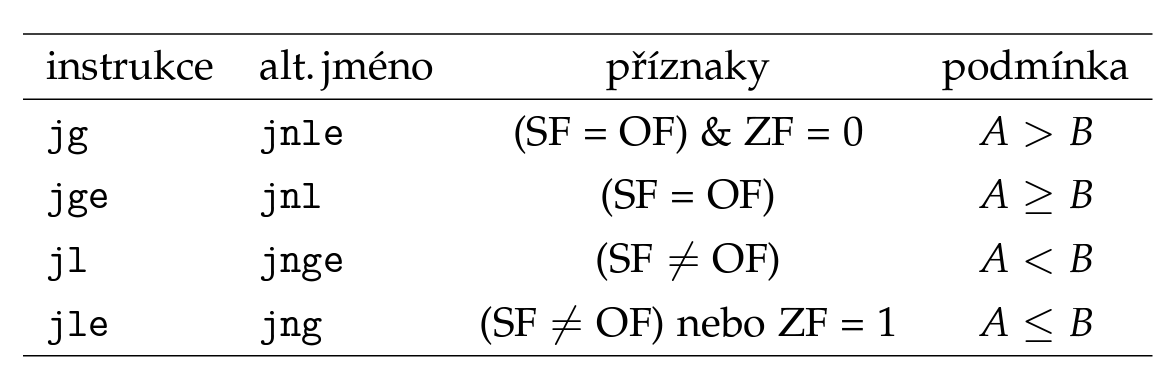
- signed
cmp a, bfunguje jakoa - b+ se nastaví příznaky vEF(ty jsou pak kontrolovány při podmíněných skocích)- zpomalují běh programu (ruší totiž výpočty v pipeline) ⇒ predikce (branch prediction)
Branch prediction
- odhad skoků
- kombinují metody (především dynamická)
- při každém průchodu procesor ukládá do branch prediction buffer
- funguje jako počítadlo
- 4 stavy (2 bity) -
00, 01, 10, 11 - pokud
00, tak předpokládá, že se skok provede - při každém skoku se hodnota zvětší a pokud se skok neprovede tak se změnší
Zásobník
- vyčleněný úsek paměti pro procesor (pomocné výpočty, návratové adresy, lokální proměnné, …)
- systém LIFO
- vyšší programovací jazyky neumožňují přímou manipulaci
- registr
ESP(vrchol zásobníku)- vždy obsahuje číslo, které je násobkem 4
mov eax, [esp]
- odebrání/vložení hodnoty (
POPaPUSHoperace) - umožňuje rekurzi
- roste shora dolů
Volání podprogramu
- na zásobník se uloží aktuálně adresa pro zpětné vrácení
- funkce
CALLslouží k volání podprogramů - funkce
RETslouží k návratu z funkce - proces volání funkcí
- předání parametrů
- tvorba lokálních proměnných
- provedení fce
- odstranění informací ze zásobníku
- navrácení hodnoty
- způsob jakým to konkrétně funguje závisí na konvenci jazyka
- C (cdecl), Pascal, fastcall
- stack frame (rámec funkce)
- vytvoří se na zásobníku při volání funkce
- obsahuje argumenty, lokální proměnné, adresu návratu
- registr
EBP
Postup pro C konvenci cdecl
Volání funkce
- na zásobník uloženy parametry funkce zprava doleva
- zavolá se funkce (
call <address>), na zásobník se uloží adresa návratu - funkce uloží obsah
EBP(obsah předchozího rámce) na zásobník - funkce uloží do
EBPobsahESP(nový rámce) - na zásobníku se vytvoří místo pro lokální proměnné
- na zásobník se uloží registry, které se budou měnit
Návrat z funkce
8) obnoví hodnoty registrů (ty co jsou na zásobníku)
9) odstranění lokálních proměnných
10) obnovení hodnoty EBP
11) návrat z funkce ret
12) odstranění argumentů ze zásobníku
- po návratu z funkce mohou registry
EAX, ECX, EDXobsahovat cokoliv - callee-saved registry … volaný se stará o uchování hodnot (pro lokální proměnné)
- caller-saved registry … volající se stará o uchování hodnot (pro dlouhodobější proměnné)
Přerušení
- způsob reakce na vnější asynchroní (neočekávané) události
- obvykle nějaký vstup (uživatel ťuknul do klávesnice, příchod paketu) potřebující CPU
- obsluha přerušení (podobná běžným funkcím)
- vždy po dokončení celé instrukce (instrukce = atomická operace)
- vyvolání přerušení → uložení stavu programu → obsluha přerušení → pokračování, tam kde CPU skončil
- souběh více přerušení ⇒ nutný řadič přerušení
- přerušení mají různou prioritu
- registr
IDTRobsahuje tabulku IDT (interupted description table), kde jsou uloženy adresy pro jejich obsluhu - obvykle v obsluze přerušení další přerušení zakázáno (povolení - bit v
EFLAGS) - návrat z přerušení pomocí
iret - využití: výjimky (dělení nulou, neplatná operace …), debugování
I/O zařízení
- spolupráce procesoru se zařízeními je obecně náročnější
- aktivní čekání
- CPU pracuje se zařízením přímo
- náročné a zastaralé
- DMA
- direct memory acces
- řadič DMA dostane požadavek na zápis/čtení + adresu paměti od CPU a po povelu se začne operace provádět
- má vlastní controller (DMAC)
- CPU předá požadavek dál a opět dostane oznámení o ukončení (v průběhu může dělat něco jiného) ⇒ zařízení pracuje s pamětí pomocí DMAC (není potřeba CPU)
- sdílení paměťového prostoru (zařízení pracují přímo s pamětí přes sběrnici)
Režimy CPU
- očekáváme
- správu paměti
- správu a sdílení procesoru
- komunikace mezi procesy
- obsluhu a organizaci dat
- není žádoucí, aby si toto zajišťoval každý program zvlášť (abstrakce)
- jádro operačního systému
- kernel (pouze jádro OS, všechna oprávnění)
- user mode (pro aplikace, něco zakázáno)
Systémová volání
- komunikace aplikace s OS pomocí přesně daného rozhraní
- přepnutí do režimu jádra (mělo by být co nejrychlejší)
- různé metody pro realizaci
- poskytovány jádrem
- voláno pomocí
syscall - poskytují základní sadu služeb (vytvoření souboru, zápis/čtení soubur, spuštění nového procesu, práce se stand. I/O atd.)
Sada procesorů x86
-
Intel x86 a AMD64
-
čísla s plovoucí řadovou čárkou
- různá velikost a přesnost (float, double, long) → různý poměr bitů pro znaménko, mantisu a exponent
- záporná nula, nekonečna, NaN
- floating point unit
- vykonává operace na číslech s plovoucí řadovou čárkou
- pracuje s 8 hodnotovým zásobníkem
-
rozdílný přístup v uložení operandů
- zásobníkový CPU
- zásobníkový je výrazně jednodušší svou instukční sadou (funguje jako zásobníkový stroj z PP)
- obvykle druhý zásobník pro funkce
push/loadapop/store
- registrový CPU
- používá registry
- dnes běžnější
AMD64
- long mode
- 64 bit mode - OS i appky v 64 bitovém režimu
- compatability mode - spustí i 32 bitové appky
- legacy mode
- umožní zpětná kompatibilita
- jak vypadá zásobník?
- zásobník zarovnán na 16B
ESP… vrchol (stack pointer) aEBP… spodek (bottom pointer)
xmm?mají 128 bitů- v linuxu je oproti windows
rdi, rsiv caller-saved + se použije u předání argumentů
Konvence pro Windows
- první 4 argumenty -
rcx, rdx, r8, r9(zbytek pře zásobník zprava doleva) - čísla s plovoucí řadovou čárkou -
xmm0 - xmm3(pokud první výskyt na 2. pozici ⇒xmm1) - návratová hodnota v
raxčixmm0 - caller-saved -
rax,rcx,rdx,r8,r9,r10,r11 - callee-saved -
rbx,rbp,rdi,rsi,rsp,r12,r13,r14,r15 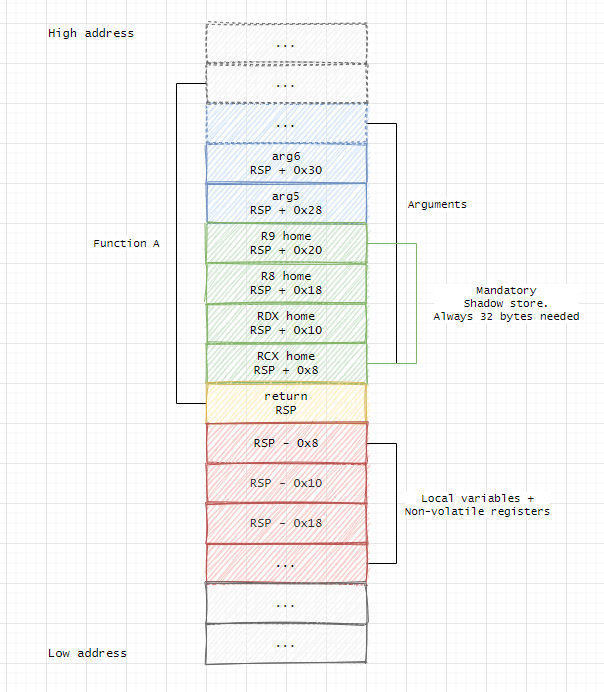
Konvence pro Linux
- prvních 6 argumentů -
rdi, rsi, rdx, rcx, r8, r9(zbytek opět přes zásobník zprava doleva) - čísla s plovoucí řadovou čárkou -
xmm0 - xmm7(použitý počet musí být vAL⇒ i na 2. pozici se začne sxmm0) - návratová hodnota
raxčixmm0 - červená zóna - oblast pod vrcholem zásobníku pro libovolné použití (128 B)
- caller-saved -
rax,rdi,rsi,rdx,rcx,r8,r9,r10,r11 - callee-saved -
rbx,rsp,rbp,r12,r13,r14,r15 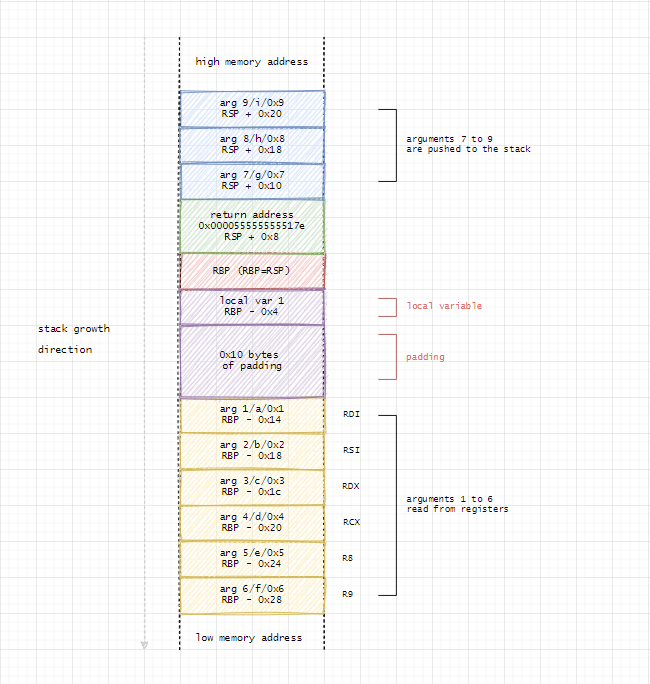
Instrukční sady ostatních procesorů
- různé syntaxe asm (Intel, AT&T)
- obě syntaxe jsou schopny zapsat to samé
- my používáme Intel
SPARC
- průmyslové procesory
- obecně se snaží být co nejjednodušší (rychlejší)
- každá instrukce 4B (zjednodušení dekódování insturkcí ⇒ vyšší rychlost)
- eliminace počtu instrukcí
- 3 operandy
- stovky registrů (běžně dostupných 32)
- globální registry
g0-g7- v
g0je vždy nula (použití například k nahrazenícmppomocísubnebomov)
- v
- registrové okno … 24 registrů - argumenty funkce, lokální proměnné, argumenty pro další funkci
- malé velikosti insturkcí přináší i nevýhody
- neumožnění adresace paměti
- přiřazení velkých čísel rozděleno do 2 kroků
- specifické provedení skoku (je zpožděn)
delay slot… instrukce zde umístěna se provede ihned po skoku bez ohledu na jeho výsledekannul bit… pro nastavení kdy provést delay slot- pro efektivitu pipeline
ARM
-
Qualcom Snapdragon, M1/2, A4-16, Exynos, …
-
embedded a přenosná zařízení
-
optimalizované na nízké zdroje (elektřina a paměť)
-
licence více výrobcům
-
celý počítač v rámci 1 čipu (“přilepeno” k sobě)
-
big LITTLE = kombinace úsporných a výkonných jader
-
různé instrukční sady
-
verze ARMv7
- 32 regisrtrů použitelných (pouze 16 v jeden okamžik)
- 32 bitů na instrukci
- barrel shifter
- možnost kombinovat operace s bitovými posuny a rotacemi (
ROR)
- možnost kombinovat operace s bitovými posuny a rotacemi (
- návratová adresa v
LR/R14 - 4 argumenty přes registry + zásobník
- thumb kódování
- jiné kódování instrukcí (možnost přepínat)
-
verze ARMv8
- 64 bitový nástupce v7 (pořád mohu použít i pouze spodní polovinu)
- instrukce opět 32 bitů
- zpětná kompatibilita přes módy
- některé vlastnosti zrušeny nebo upraveny
- 8 argumentů přes registry + zásobník
-
RISC (reduced instruction set) a CISC (complete instruction set)
- vnitřně je CISC vlastně RISC
- např. násobení jde nahradit na sčítání a bitové posuny
- CISC nemá větší počet absolutních instrukcí (těch vykonávatelných přímo na CPU)
- provádí se úpravy na kódu (abstrakce)
- RISC má složitější instrukce rozložené do posloupnosti jednodušších
- CISC bližší vyšším jazykům
- OoO (out of order execution) … rozdělení operací mezi jednotky = paralelismus
- vnitřně je CISC vlastně RISC
-
VLIW … very long isntruction word
- 1 instrukce má více operací ⇒ souběžné zpracování
- na paralelismu se spolupracuje s překladačem
Překlad programu
- několik postupných částí (mohou být vynechány či sloučeny)
- preprocesor - makra, odstranění komentářů, načtení hlavičkových souborů atd.
- překladač - generuje ASM
- assembler - generuje objektový kód
- linker - sloučí objektové kódy + knihovny do spustitelného programu
- kroky mohou být sloučeny do jednoho
- vyšší jazyky nejdříve přeloženy do nižšího
- možnost kombinace více jazyků
- pokud ve výsledku dostanu spojitelné objektové soubory
- např. to co jsme dělali
ASM + C
Knihovny
Staticky linkované knihovny
- před použitím se musí spojit s naším kódem
- vzniká 1 celek
- výhody: jednoduchost, bez režie při běhu
- nevýhody: spotřebuje více paměti, při její aktualizaci je nutnost rekomplilace, každý program má svojí kopii
Dynamicky linkované knihovny
- forma spustitelného programu
- obecně větší provázanost s OS a kódem
- rozdíl v řešení mezi UNIX a Windows
- UNIX
- sdílené knihovny (shared object)
- PIC - lze spustit bez ohledu na adresu v paměti
- x86 má relativní adresování (vůči něčemu)
- global offset table (GOT)
- slouží k výpočtu absolutní adresy (pro přístup ke globálním proměnným)
- tabulka je někde uložena (známe místo) a vezme se z ní potřebná adresa
- procedure linkage table (PLT)
- volání funkce → skok do PLT –> nastaví se záznam o funkci pro linker → linker → linker najde adresu v GOT → nastaví ji do PLT → spuštění funkce
- opakované spuštění již bez GOT (adresa je v PLT)
- Windows
- dynamic link library
- každá knihovna má vlastní adresu v paměti
- kolize ⇒ nutnost přepočítání a přesunu
- import address table - adresy volaných funkcí
- inicializace při spuštění
- thunk table … tabulka thunk funkcí pro funkce v knihovnách, slouží jako prostředník mezi naším kódem a knihovnou
Dynamicky nahrávané knihovny
- možnost explicitně nahrát knihovny za běhu (poté je mohu zase z paměti uvolnit)
- knihovna není dostupná → použít alternativní či oznámení uživateli
- podobné jako dynamické linkování
- UNIX -
dlopen, dlsym - Windows -
LoadLibrary, GetProcAddr - vhodné pro implementaci specifických pluginů/modulů
Virtuální stroje
- virtualizace systému vs procesu
- několik problémů - binární soubory pro konkrétní procesor,
- řešení - nepřekládat program do strojového kódu cílového procesoru, ale do bytecode (instrukční sada virtuálního procesoru)
- následně bytecode interpretujeme nebo ho přeložíme na cílový procesor
- umožnění tvorby přenositelného kódu (nezávislý na CPU)
- lepší kontrola běhu programu
- ale je to režie navíc
JIT překladač
- just in time
- běhově prostředí je tedy generováno za běhu
- sleduje co je často (ne)používáno ⇒ optimalizace
- obvykle u překladu bytecode → strojový kód
- Zásobníkové VM
- jednoduchá instrukční sada
- už podle názvu neobsahuje registry a vše je na zásobníku
- operandy na jeho vrcholu (implicitní)
- JVM, CLR
- Registrové VM
- efektivní překlad do instrukční sady procesorů
- odolnější vůči chybám
- LLVM, Dalvik
JVM a Java Bytecode
- java virtual machine
- překlad Java → Java Bytecode → vykonání pomocí JVM
- JVM umí zpracovat i kódy z jiných jazyků
- umožňuje přenositelnost mezi platformami (stačí, aby tam fungoval JVM)
- malý počet instrukcíc (<256)
- pracuje se 2 zásobníky
- jednoduché i velmi komplexní operace
- speciální operace pro určité věci (práce s 1 a 0, prvním argumentem)
CLR a CLI
- common language runtime a common intermediate language
- .NET implementuje podobný přístup jako Java
- CLR + CLI = běhové prostředí + bytecode
- koncepčně podobné JVM a JBC
- podporuje více jazyků
- just in time
- převádí zdrojový kód do procesorového kódu
- poskytuje taktéž podpůrné služby - správa paměti, správné typování, garbage collector, zpracování vyjímek
Architektura OS a jádra
Monolitické jádro
- vrstvená architektura
- služby jsou pohromade ⇒ lepší výkon
- většina běží v kernel módu
- má sdílený paměťový prostor
- rozhraní mezi OS a procesy poskytují systémová volání
- typické u UNIXu
Mikrojádro
- velmi malé (obsahující pouze to nejnutnější)
- správa adresního prostoru, správa procesů, IPC (inter process communication)
- ostatní věci běží v uživatelském režimu
- schopnost pozastavit/restartovat jednotlivé servery
- MINIX, Symbian OS
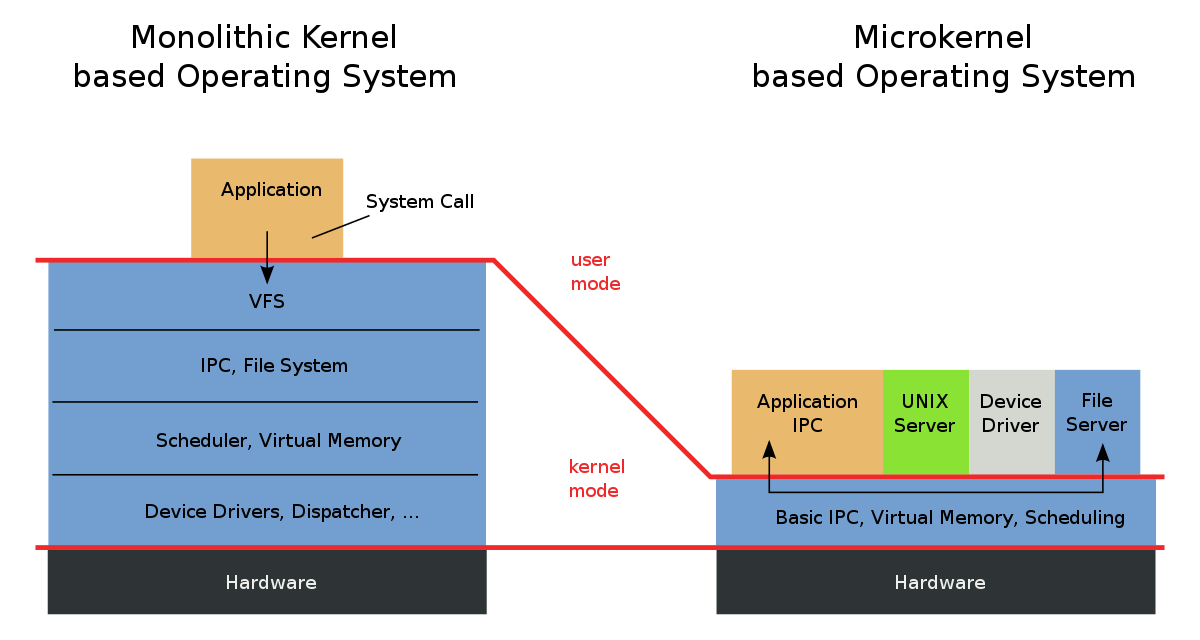
Hybdridní jádro
- kombinace obou přístupu
- Windows, macOS
Exokernel
- prakticky bez abstrakce
- umožňuje aplikacím co nejbližší přítup k HW
Základní vlastnosti UNIXů
- více uživatelský přístup (spíše zkušenější uživatel)
- vrstvená architektura + pojící prvky
- systémová volání
- volání knihoven
- systémové nástroje
- uživatelské aplikace
- dlouhá životnost
- všechno je soubor
- FreeBSD, NetBSD, GNU xxx, XNU/Darwin
Vlastnosti Windows NT
- kompatabilita s ostatními verzemi
- objektový přístup
- implementace v C/C++
- hybridní architektura
Windows Executive
- klíčová část OS - poskytuje funkce do uživatelského prostoru
- jednotlivé části jádra - registry, různé managery (memory, I/O, cache, process thread, …)
Android a iOS
- vychází z Linux respektive Darwinu
- používají jiný userland
Procesy
- proces se dá chápat jako běžící program (sekvence instrukcí v 1 paměťovém prostoru)
- proces charakterizuje
- kód programu
- paměťový prostor
- data
- zásobník
- registry
- jsou organizovány operačním systémem
- více procesů ⇒ vzájemné komunikace ⇒ synchronizace
Životní cyklus procesu
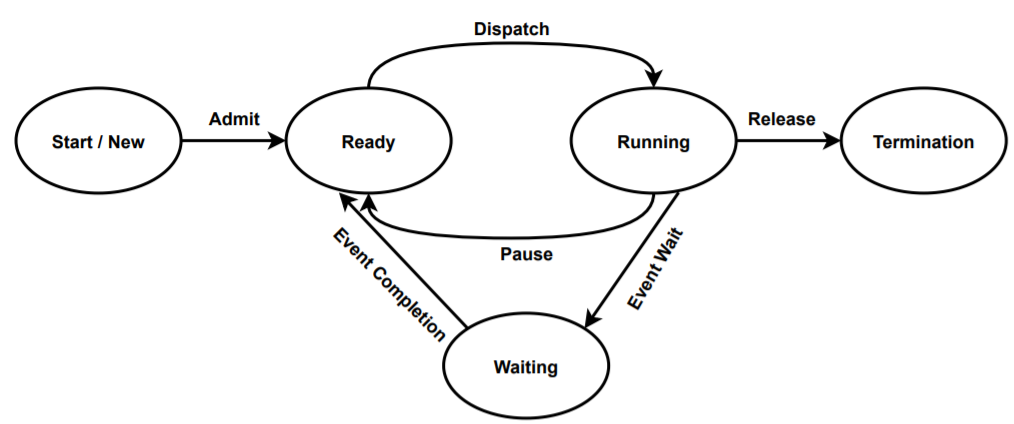
Informace o procesu
- v tabulce procesů - PCB (process control block)
- identifikace (identifikátor, rodičovský proces)
- stavové informace - stav registrů a zásobníku
- řídící informace - slouží k plánování
- stav, priorita, oprávnění, používající I/O, přidělená paměť
Přepínání procesů
- context switch
- postup
- uložení stavu CPU (aktuálního procesu) do PCB
- aktualizace PCB
- zařazení procesu do příslušné fronty
- volba nového procesu
- nastavení potřebných datových struktur pro nový proces
- načtení kontextu nového procesu z PCB
- kontext (stav) - obsah registrů, cache procesoru - prostě vše co je nutné, aby proces a procesor mohl pokračovat tam kde skončil
- důvody pro přepnutí - vypršení časového kvanta, přerušení I/O zařízení, výjimka
- kooperativní … program se musí sám zříct času na CPU
- premptivní … OS odebere programu čas na CPU
Plánování procesů
- dbá na efektivitu (i přepnutí má svou režii)
- časové kvantum … maximální čas přidělený procesu
- problém v poměru efektiva / odevedená práce
Typy plánování
- Dlouhodobé - rozhoduje zda bude přijat k běhu (new → ready)
- Střednědobé - načítání/odklad do sekundární paměti (swapování)
- Krátkodobé - z připravených vybere ten, který dostanu čas na CPU
- I/O - rozhoduje požadavky na I/O
-
rozhoduje i typ systému (interaktivní, dávkové či real-time)
-
CPU I/O burst cycle
- cyklické střídání požadavků na CPU a na I/O
- procesor přepíná mezi těmito 2 burst stavy
-
na plánování jsou kladeny požadavky (částečně si navzájem odporují)
- spravedlnost, vyváženost, efektivita, maximalizace odvedené práce, minimalizace odezvy, minimalizace doby průchoduz systémem
Algoritmy pro plánování
- First comed first served
- první proces získá procesor, zbytek čeká ve frontě
- Shortes job first
- vybírá proces, který spotřebuje nejméně času
- dobrá průchodnost, ale je nutno odhadnout potřebný čas
- Shortest remaining time next
- pokud následující potřebuje méně času, tak je přepnut
- Round robin
- každý proces má časové kvantum (> než je nutné)
- zbytek řazen ve frontě
- je spravedlivý
- Prioritní fronta
- každý proces má danou prioritu (dána staticky či dynamicky, po I/O vyšší)
- pro každou prioritu zvlášť fronta
- procesy s nízkou prioritou mohou vyhladovět
- Shortes process next
- odhad podle předchozí aktivity procesu
- vhodný pro interaktivní OS
- Guaranteed scheduling
- každý proces dostane stejně času → postupně se určuje poměr kolik času měl vs kolik potřeboval
- volí se ten co má poměr nejmenší
- Lottery scheduling
- náhodně volení losů (možnsot výměny losů mezi procesy)
- Fair share scheduling
- podle skupin procesů
-
speciální typ jsou úlohy běžící v reálném čase
-
důležité zareagovat na požadavek v daném intervalu
- soft a hard verze
-
varianty plánování
- statická - dáno předem či nastavení priority
- dynamická - řeší se zda je možné splnit požadavky
Vlákna
- procesy jsou od sebe izolovány (výhoda při vývoji softwaru)
- dnes používáme obecnější přístup
- proces … základní jednotka starající se o správu zdrojů
- samotný kód, který se vykonává je řešen pomocí vláken
- vlákno má vlastní registry, zásobník, IP, stav
- avšak vlákna sdílí stejné globální proměnné ⇒ žádná ochrana ⇒ nutnost synchronizace
- různá vztahy proces-vlákno
- 1:1
- 1:N (nejčastěji používané)
- M:N
Implementace vláken obecně
- jako knihovna v uživatelském prostoru
- proces se sám stará o práci s vlákny
- kooperativní přepínání (vyšší rychlost a menší režie)
- můžeme si sami zvolit algoritmus pro přepínání
- nevýhodou je, že OS je od vláken distancovaný a nich o nic neví
- použití: když mám veliký počet (> řádově tisíce) různých úloh
- součást OS
- v jádře
- spravováno podobně jako pro procesy (registry, stav)
- je o něco pomalejší
- možná i kombinace obou řešení (hybridní)
- proces má M vláken v jádře, kde má každé N vláken uživatelského prostoru
- v OS na ústupu, obnovení v Golang
Implementace v UNIXu
- identifikace pomocí
PID - při inicializace spuštěn proces
init fork()vytvoří nového potomka (kopie rodiče)
pid_t n_pid = fork();
if(n_pid < 0){
// chyba
}
else if(n_pid == 0){
// kod potomka
}
else {
// kod rodice
}-
exec()… nahraje kód do paměti a spustí ho -
vztah rodič-potomek přináší sdílení některých zdrojů
-
sirotek … rodič skončil dřív (přejde pod
init) -
zombie … skončil, ale v systému existuje
-
vlákna dodána až později (dříve v knihovnách)
-
rozdíl mezi synchronizací vláken a procesů
-
pthread -
plánování pracuje s vlákny i procesy stejně (
task) -
různé stavy úloh - running, ready, sleeping (waiting for HW nebo waiting for condition),
-
clone… zobecněnífork- umožní vybrat co sdílet
-
je možné vybrat i typ plánovače
-
Completely fair scheduler
- v RB-tree
- organizovány podle kolik dostaly času
- vybrán ten, který ho získal nejméně (nejvíce levý list)
- automaticky vyvažovaný
- v RB-tree
Implementace ve Windows
- vlákno - základní jednotka (účastní se plánování)
- proces - obsahuje více vláken (společné zdroje)
- job - více procesů
- fiber - něco jako vlákna v uživatelském prostoru (odlehčené vlákno), běží v rámci 1 vlákna
- plánování je řešeno pomocí prioritní fronty
- klasická fronta , abych toho samého dosáhl u prioritní vytvořím front pro priorit a vždy přidávám/odebírám z dané fronty (další vylepšení pomocí bitmapy)
- při vzniku není vyžadován vztah rodič-potomek
CreateProcess… vytváří procesCreateThread… vytváří vlákno- různé stavy vláken
- initialize - inicializováno, ale ještě není připraveno, aby z mohlo být vybráno
- ready - čeká na spuštění od CPU
- standby - vlákno připravující se k použití od CPU (pouze 1 v okamžik)
- running
- waiting - čeká na I/O či na volný zdroj
- terminated - ukončené
- priority vláken
- objevení vlákna s vyšší prioritou → přepnutí
- hodnoty
- určujíc se z tříd pro priority procesu (procesy = třídy, vlákna = čísla ve třídách)
- třídy se mohou částečně překrývat
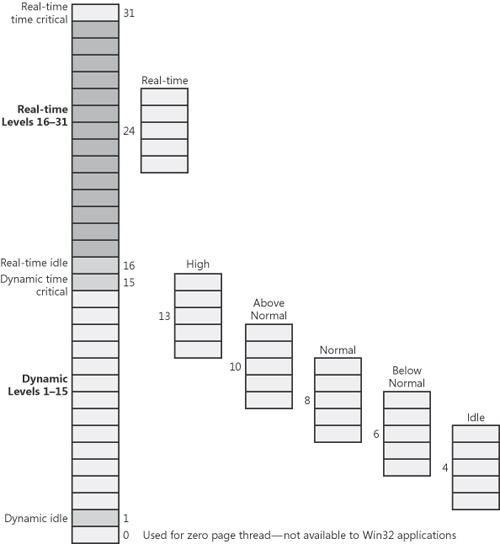
- priority boost (dočasné zvýšení) - práce s I/O
- velikost kvanta
- zavisí na verzi
- jde měnit
- přepnutí/čekání → snížení
- obecně plno pravidel a “výjimek”
- pokud vlákno dlouho neběželo (sekundy) ⇒ rapidně roste priorita i kvantum
Implementace v macOS
- vychází z UNIX
- víceúrovňová fronta
- Grand Central Dispatch - propojení OS a prog. jazyků
- umožní provádění bloků kódů ve vláknech
- komfortnější z pohledu programátora ()
Víceprocesorové systémy
- SMP (symmetric multiprocessing) - dominantní řešení ovládání víceprocesorů
- další procesory (jádra) aktivovány podle potřeby
- velmi složitá problematika
- každé jádro = vlastní plánovač + sada procesů (oddělení)
- nemusí být vždy vhodné - nerovnoměrně vytížené procesory
- ⇒ vyvažování úloh mezi procesory
- migrování procesů mezi procesory → horší využití cache
- komplikováno hybridní architekturou procesoru (různé rozdělení jader - úsporná a výkonná)
Synchronizace vláken a procesů
- přistupují ke sdíleným zdrojům ⇒ problémy (PP4)
- současné zvýšení proměné (ABA problém)
- obecně jsou chyby špatně odhalitelné (nemusí se objevit vždy - závisí na konkrétním běhu programu)
- řešení atomické operace (jsou omezené ⇒ pouze specifické případy)
- umožňují zavést synchronizační mechanismy
- race condition … postup zpracování je nevhodný tudíž dojde k neočekávanému výsledku
Atomické operace
- test and set - použit v semaforech
- swap
- compare and swap
- fetch and add
- load link/store conditional
Kritická sekce
- část programu, kde se praucje se sdílenými zdroji
- sdílená paměť ⇒ pracuje jen 1 proces najednou
- cache
- vzájemné vyloučení (mutex)
- sdílený prostředek může užívat pouze 1 proces v 1 okamžik
- problém kritické sekce má svá pravidla
- pouze 1 proces najednou uvnitř sekce
- zbytečně nebrání ve vstoupení (pokud tam nikdo není)
- zaručený vstup - proces tam vždy v konečném čase vstoupí
- i v kontextu jádra OS
- synchronizace uživatelských procesů (či vláken)
- 2 typy jader pro řešení
- neprempitvní jádro - starší, jednodušší, pokud jádro běží v kernelu nejde přepnout
- premptivní jádro - dnes většina, nutno řešit kritickou sekci i v kernel modu
Řešení
- Zablokování přerušení (použitelné jen v jádře OS, pro jednodušší OS)
- Aktivní čekání (spinlocks)
- řešení č.1 je špatně (race condition)
- instrukce
test_and_set(musí být atomická) k implementaci zámků
- Založené na atomické operaci
swap - Petersonův algoritmus (není důležité znát)
- nepoužívá atomické operace
- vyžaduje férový plánovač
- v praxi jsou nepoužitelný
- Semafor
- operace
P(bere zdroj) aV(uvolňuje zdroj) - pasivní čekání
- seznam čekajících procesů (FIFO - fronta)
- viz PP4
- operace
- RW locks (read-write lock)
- Monitor (objekt)
Synchronizační primitiva ve Windows
- objekty ve 2 stavech (signalizovaný a nesignalizovaný)
- signalizovaný objekt je dostupný a může být synchronizován
- můžeme vytvářet objekty sloužící k synchronizaci (synchronizace v rámci procesu, po pojmenování i mezi procesy)
Synchronizační primitiva v UNIXu
- není to tak jednoduché a přímočaré jako ve Win
- pro atomické operace chybí rozhraní v uživatelském prostoru (standardně nejsou k dispozici, nutno použít knihovny)
- jádro má vlastní operace
Deadlock
- uváznutí = systém ve stavu kdy nemůže pokračovat
- má určité podmínky vzniku
- mutual exclusion (mutex) - alespoň 1 prostředek je výlučně užíván 1 procesem
- hold and wait - proces vlastní prostředky a čeká na další
- no preemption - prostředek nelze násilně odebrat
- circular wait - vzájemné vlastnění a čekání (pokud je toto splněno již vznikl)
- A má 1 a čeká na 2, B má 2 a čeká na 1
Řešení
- v praxi se často používá neřešení problému (ignorace)
- detekce a zotavení
- detekování → některý proces odstraněn nebo mu odebrán zdroj nebo vrácení zpět
- používá orientované grafy (pokud cyklus tak deadlock) - graf prostředků a graf
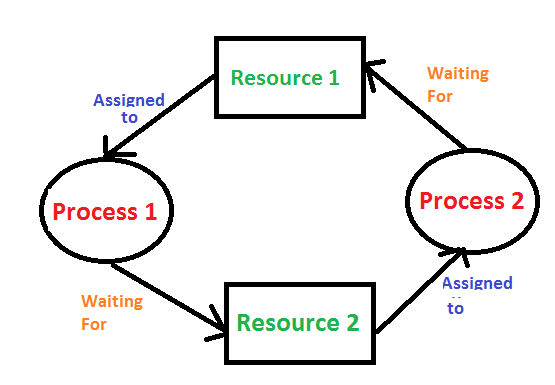
- zamezení vzniku
- snažíme se zajistit NEsplnění nějaké podmínky
- např. procesy budou žádat o všechny prostředky hned na začátku nebo pořadník pro čekání
- snažíme se zajistit NEsplnění nějaké podmínky
- vyhýbání se uváznutí
- vyhoví se pouze těm požadavkům, které nemohou vést k uváznutí